Problem Statement: Defining vulnerabilities scorecard weights through expert judgment
In humanitarian contexts, it’s not always possible to use a statistically representative dataset in order to infer the relative weights to be used for each criteria from the full vulnerability scorecard. The only options is to use multiple expert judgement in order to Define relative weights to be used for each criteria when designing composite indicator for vulnerability measurement.
Often teams of expert suffer from non-aligned goals, power politics, group dynamics and lack of mutual understanding, which comes though with specific challenges:
- How expert can come up with values for the weight?
- How to reach consensus among expert on the suggested values on complex decisions in order to raise sufficient confidence in decision outcomes?
- Is there an alternative to lenghty consensus building?
What is Analytic Hierarchy Process (AHP)?
Analytic Hierarchy Process (AHP) is structured technique, developed in the 70’s by Thomas Saaty in Wharton Business School ( Decision Making for Leaders: The Analytic Hierarchy Process for Decisions in a Complex World), for organizing and analyzing complex decisions, based on mathematics and psychology . It is a comprehensive and rational framework to organize feeling, intuition & logic for structuring group decision making. Rather than prescribing a “correct” decision, the AHP helps decision makers find one that best suits their goal and their understanding of the problem.
Comparisons are made to define priorities between 2 alternatives based on decision-maker’s feeling of priority dues to importance, preference and likelihood of influence. This breaks down complex decision into small judgement.
AHP also comes with the following limitations:
- Assumes a minimum level of judgement consistency among experts
- Limited number of criteria to minimize the number of pairwise comparison estimation -
- Data should be available for all criteria
- Assumes that when new alternatives are added to a decision problem, the ranking of the old alternatives is not changing
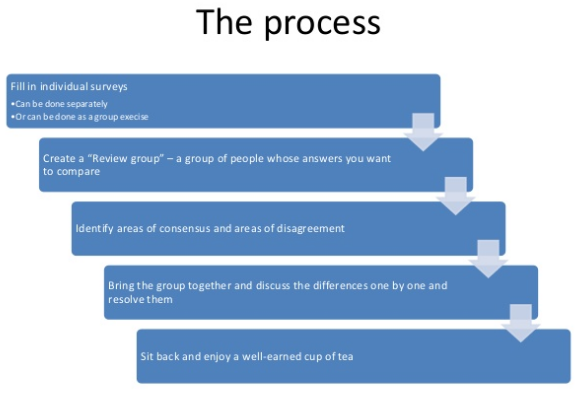
In order to use AHP, the following steps can be used:
- Define vulnerability criteria
- Build the expert consultation form
- Generate the AHP file from the collected data
- Run AHP algorithm
- Review results
- Apply the formula
knitr::opts_chunk$set(
collapse = TRUE,
comment = " "
)
## This function will retrieve the packae if they are not yet installed.
using <- function(...) {
libs <- unlist(list(...))
req <- unlist(lapply(libs,require,character.only = TRUE))
need <- libs[req == FALSE]
if (length(need) > 0) {
install.packages(need)
lapply(need,require,character.only = TRUE)
}
}
## Getting all necessary package
using("readxl", "readr", "tidyverse", "openxlsx", "readxl", "yaml", "ahp", "R6", "data.tree")
rm(using)1. Define vulnerability criteria
List potential criteria that would contribute to vulnerability within the current context. Note that criteria can be grouped together using hierarchy.
Establish freehold for criteria so that they can be formulated as simple binary questions
Criteria without hierarchy
In this case N*(N-1)/2 pairs to review: 5 criteria -> 10 comparisons
| Criteria-Code | Criteria-Level-1-label | Criteria-Level-2-label |
|---|---|---|
| age | Age of head of household is above 50 | |
| gender | Gender of head of household is female | |
| size | Household size is above 5 | |
| needs | Occurrence of Specific needs | |
| assistance | Do not Receive assistance |
PS: 6 criteria -> 15 comparison, 7 criteria -> 24 comparisons, 8 criteria -> 28 comparisons, 9 criteria -> 36 comparisons
Criteria with hierarchy
In this case 6 pairs to review…
| Criteria-Code | Criteria-Level-1-label | Criteria-Level-2-label |
|---|---|---|
| age | Demography | Age of head of household is above 50 |
| gender | Demography | Gender of head of household is female |
| size | Demography | Household size is above 5 |
| needs | Occurrence of Specific needs | |
| assistance | Do not Receive assistance |
2. Build the expert consultation form
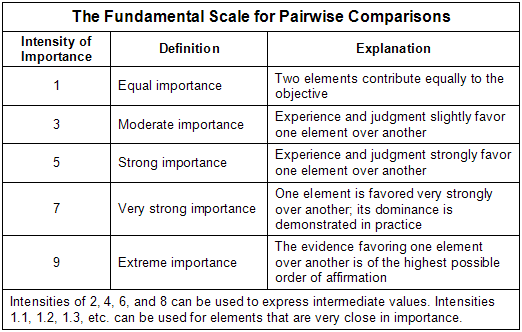
A form will allow to collect from expert priorities between criteria by making a series of judgments based on pairwise comparisons:
Collect judgment for all pairwise comparison and each expert
Ranking Scales for Criteria
The function below allows to build a xlsform file based on criteria defined above. The input file here is a csv file with two columns: - name: a short variable name for analysis purposes only - label: the long description printed on the form
Criteria should be saved in a configuration file using the format here ahpCriteria.csv.
criteria_to_xlsform <- function(critf) {
criteria <- read_csv(critf)
crit <- set_names(criteria$label, criteria$name)
blank <- "<span style='display:none'>foo</span>"
intro <-
str_c(
"THANK YOU FOR PARTICIPATING IN THE CRITERIA COMPARISON EXERCISE.",
"THE FOLLOWING SURVEY HAS BEEN DESIGNED TO HELP YOU RECORD YOUR OPINION.",
sep = " "
)
survey <-
cross_df(names(crit) %>% list(crit1 = ., crit2 = .)) %>%
filter((row_number() - 1) %>% {. %/% length(crit) > . %% length(crit)}) %>%
transmute(
criteria =
map2(crit1, crit2,
~tibble(
type = c("note", "select_one priority", "note", "select_one importance"),
name = str_c(c("note", "prio", "blank", "imp"), "_", ..1, "_x_", ..2),
label = c(str_glue("__Compare__ {crit[..1]}\n__with__ {crit[..2]}"),
blank, blank, blank),
appearance = c("w1", "w1 likert", "w2", "w2 horizontal-compact"),
relevant = c(NA, NA,
str_c("${prio_", ..1, "_x_", ..2, "} = '", c('', '0'), "'",
collapse = " or "),
str_c("${prio_", ..1, "_x_", ..2, "} = '", c('1', '-1'), "'",
collapse = " or ")),
required = c(NA, TRUE, NA, TRUE)))) %>%
unnest()
survey <-
bind_rows(
tribble(
~type, ~name, ~label, ~appearance,
"note", "intro", intro, NA,
"begin_group", "criteria", "Criteria", "w4",
"note", "compare", blank, "w1",
"note", "priority", "__Priority__", "w1",
"note", "importance", "__Importance__", "w2"
),
survey,
c("type" = "end_group")
)
choices <-
tribble(
~list_name, ~name, ~label,
"priority", 1, "1st",
"priority", 0, "equal",
"priority", -1, "2nd",
"importance", 3, "moderate",
"importance", 5, "strong",
"importance", 7, "very strong",
"importance", 9, "extreme"
)
settings <- tibble(style = "theme-grid")
xlsform <- createWorkbook()
addWorksheet(xlsform, "survey"); writeData(xlsform, "survey", survey)
addWorksheet(xlsform, "choices"); writeData(xlsform, "choices", choices)
addWorksheet(xlsform, "settings"); writeData(xlsform, "settings", settings)
saveWorkbook(xlsform, "ahp_form.xlsx", overwrite = TRUE)
}
## Now run the function
critf <- "ahpCriteria.csv"
criteria_to_xlsform(critf)
Form
The form ahp_form.xlsx can be used within UNHCR Kobo server. Experts can be humanitarian case workers that are used to assess vulnerability.
See an example here

3. Generate the AHP file from the collected data
Once the selected experts (aka. decision-makers) have filled the online form , data can be exported from UNHCR Kobo server in csv format.
A new function allows to create the AHP file.
This create the file that format correctly the pairwise preferences of each decision-makers to run the next step. The input file is the survey data collected in kobotoolbox (do NOT use group names when extracting the data!).
survey_to_ahptree <- function(dataf) {
data <- read_delim(dataf, ";", escape_double = FALSE, trim_ws = TRUE)
data <- data %>% select(matches("^(prio|imp)_")) %>% mutate_all(as.numeric)
data <- data %>%
mutate(respondent = str_c("respondent_", row_number())) %>%
gather(key, val, -respondent) %>%
extract(key, c("measure", "crit1", "crit2"), regex = "(.*)_(.*)_x_(.*)") %>%
spread(measure, val) %>%
mutate(pref = case_when(prio == 1 ~ imp,
prio == 0 ~ 1,
prio == -1 ~ 1/imp)) %>%
select(-prio, -imp)
criteria <- union(data$crit1, data$crit2)
respondents <- unique(data$respondent)
data <-
data %>%
nest(-respondent) %>%
mutate(prefs = map(data, ~list(pairwise = pmap(., ~list(...)))))
goal.preferences <- set_names(data$prefs, data$respondent)
cases <-
rep(list(c(0, 1)), length(criteria)) %>%
set_names(criteria) %>%
cross_df()
caseids <-
str_c("case", str_pad(seq_along(pull(cases)), ceiling(log10(2^length(criteria))), pad = "0"))
cases %>% mutate(id = caseids) %>% write_csv("cases.csv")
alternatives <-
cases %>%
pmap(~list(...)) %>%
set_names(caseids)
goal.children <-
cases %>%
map(
~list(
preferences =
rerun(
length(respondents),
list(score = map2(., caseids, ~set_names(list(.x),.y)))) %>%
set_names(respondents),
children = alternatives))
ahptree <-
list(
Version = 2.0,
Goal =
list(
name = "Vulnerability ranking",
preferences = goal.preferences,
children = goal.children))
ahptree %>% write_yaml("ahpTree.ahp")
}
dataf <- "ahpData.csv"
survey_to_ahptree(dataf)4. Run AHP algorithm
- Calculation done using R statistical language.
- Synthesize these judgments to yield a set of overall priorities
- Check judgments consistency (consistency ratio)
- Compute weights for each expert
- Mathematical calculations to convert these judgments to priorities for each of the four criteria
levelName
1 Vulnerability ranking
2 ¦--age
3 ¦--gender
4 ¦--need We can visualize the model
We can now see the output from the model
| Weight | case32 | case30 | case31 | case24 | case28 | case16 | case29 | case22 | case23 | case26 | case27 | case20 | case14 | case15 | case08 | case12 | case21 | case25 | case18 | case19 | case13 | case06 | case07 | case10 | case11 | case04 | case17 | case05 | case09 | case02 | case03 | case01 | Inconsistency | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vulnerability ranking | 100.0% | 6.2% | 5.2% | 5.2% | 5.1% | 4.9% | 4.7% | 4.1% | 4.0% | 4.0% | 3.9% | 3.8% | 3.7% | 3.6% | 3.6% | 3.5% | 3.4% | 2.9% | 2.8% | 2.7% | 2.6% | 2.5% | 2.4% | 2.4% | 2.3% | 2.3% | 2.2% | 1.6% | 1.3% | 1.2% | 1.1% | 1.1% | 0.0% | 106.6% |
| dependency | 25.2% | 1.6% | 1.6% | 1.6% | 1.6% | 1.6% | 0.0% | 1.6% | 1.6% | 1.6% | 1.6% | 1.6% | 1.6% | 0.0% | 0.0% | 0.0% | 0.0% | 1.6% | 1.6% | 1.6% | 1.6% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 1.6% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | NA |
| need | 21.0% | 1.3% | 1.3% | 1.3% | 1.3% | 0.0% | 1.3% | 1.3% | 1.3% | 1.3% | 0.0% | 0.0% | 0.0% | 1.3% | 1.3% | 1.3% | 0.0% | 1.3% | 0.0% | 0.0% | 0.0% | 1.3% | 1.3% | 1.3% | 0.0% | 0.0% | 0.0% | 0.0% | 1.3% | 0.0% | 0.0% | 0.0% | 0.0% | NA |
| size | 19.2% | 1.2% | 1.2% | 1.2% | 0.0% | 1.2% | 1.2% | 1.2% | 0.0% | 0.0% | 1.2% | 1.2% | 0.0% | 1.2% | 1.2% | 0.0% | 1.2% | 0.0% | 1.2% | 0.0% | 0.0% | 1.2% | 0.0% | 0.0% | 1.2% | 1.2% | 0.0% | 0.0% | 0.0% | 1.2% | 0.0% | 0.0% | 0.0% | NA |
| age | 17.5% | 1.1% | 1.1% | 0.0% | 1.1% | 1.1% | 1.1% | 0.0% | 1.1% | 0.0% | 1.1% | 0.0% | 1.1% | 1.1% | 0.0% | 1.1% | 1.1% | 0.0% | 0.0% | 1.1% | 0.0% | 0.0% | 1.1% | 0.0% | 1.1% | 0.0% | 1.1% | 0.0% | 0.0% | 0.0% | 1.1% | 0.0% | 0.0% | NA |
| gender | 17.2% | 1.1% | 0.0% | 1.1% | 1.1% | 1.1% | 1.1% | 0.0% | 0.0% | 1.1% | 0.0% | 1.1% | 1.1% | 0.0% | 1.1% | 1.1% | 1.1% | 0.0% | 0.0% | 0.0% | 1.1% | 0.0% | 0.0% | 1.1% | 0.0% | 1.1% | 1.1% | 0.0% | 0.0% | 0.0% | 0.0% | 1.1% | 0.0% | NA |
An interactive interface is available to interact with results.
Lack of consistency is often observed
If consistency ratio is above 0.1, then judgement are untrustworthy because they are too close to randomness -> exercise needs to be repeated or abandoned.
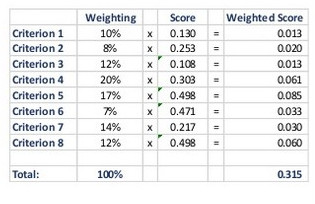
Once sufficient consensus has been reach, one just needs to apply the formula - Calculate mean relative weight - Apply the vulnerability formula - Collect data on each criteria for all household - Apply weight to each record for the different criteria to get the vulnerability level of each household
Thanks to Christoph Glur for developing the original AHP package and answering questions.
Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email